Reactive API Service — Using Spring Webflux and Reactive Data Redis

When developing microservice, it is desirable to use a non-blocking approach to build some services that have large traffic. This enables them to be elastic, that is, scalable, responsive and resilient, meaning that they will be tolerant of failures. Elasticity and resilience together will enable a reactive system to be responsive; they will be able to respond in a timely fashion.
In this excerpt, I will show you how to integrate Redis reactively (non-blocking) with a reactive Spring user-service that runs asynchronously.
This is not a tutorial to Project Reactor/Spring Webflux or how to develop non-blocking APIs or Redis service or clusters there are lots of tutorial on the internet for that. Spring also have a simple but not explanatory tutorial on this at https://spring.io/guides/gs/spring-data-reactive-redis/
I will follow these 10 steps to explain how I implemented the project.
- Simple user-service webflux API.
- Adding maven dependencies for both the spring-webflux and reactive data Redis.
- Project architecture and structure
- Adding the Spring and the Redis properties to the project properties file.
- Adding the User model/entity class.
- Configuring Reactive Redis with Lettuce Connection factory and Redis serialization.
- Implementing ReactiveCrudRepository interface and integrating it with Reactive Data Redis.
- Designing deligating service and controller layers.
- Writing the persistence tests to test the implemented UserRepository.
- Conclusion.
To follow along, you will need to download or clone the final project on GitHub at https://github.com/HabeebCycle/spring-reactive-redis-api
Step 1. Creating a Maven Spring Boot project
We start by going to https://start.spring.io/ to bootstrap the project.

I am using Java 11 as the language, Maven as the project tool, Spring Boot 2.4.2 and Packaging as a jar.
Complete the Project Metadata as you like, don’t worry about adding any dependencies now we will add them later. Go ahead and click the ‘Generate’ button to download the zip file for the project.
Extract the zip file and open the POM file with your favourite IDE as a Maven project. This will take several minutes if this is the first time you are developing a spring-boot project. You should see something like below:
Step 2: Add the Maven dependencies
Remove the default added dependencies and the following dependencies to the pom.xml file
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId> </dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId> </dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency> <!-- Embedded Redis for testing purposes-->
<dependency>
<groupId>it.ozimov</groupId>
<artifactId>embedded-redis</artifactId>
<version>0.7.3</version>
<scope>test</scope>
</dependency>
Your final pom.xml should look like the following:
We are using this dependency spring-boot-starter-data-redis-reactive to access Redis reactively and spring-boot-starter-webflux for the non-blocking API using project reactor.
Dependency spring-boot-starter-test is used for testing with JUnit5 while reactor-test will be used for StepVerifier testing for non-blocking API.
I have added the following dependency to allow testing with embedded Redis server.
<dependency>
<groupId>it.ozimov</groupId>
<artifactId>embedded-redis</artifactId>
<version>0.7.3</version>
<scope>test</scope>
</dependency>Step 3: Project Architecture and Structure
When developing a restful service, I always like to configure my project to follow a certain convention i.e. separating concerns. Different packages will hold what business they do. This is not a fast and hard rule, but it is very important in professional development to separate concerns as this will help us to scale any project.
The structure will look as shown below:
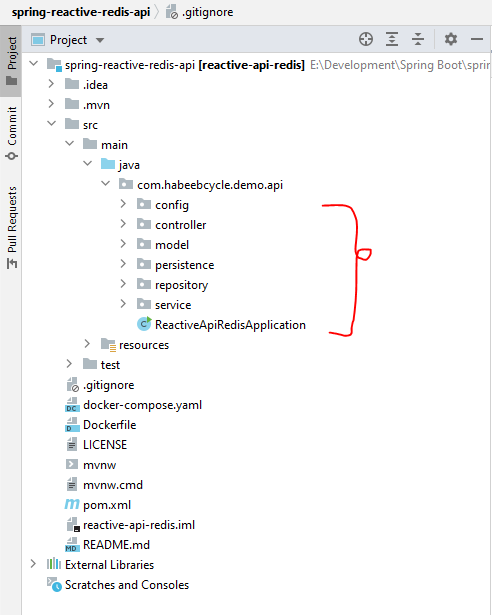
The config folder will hold all the configurations, the controller will hold all the web interface that map the endpoints, the model will hold the entities, persistence will hold any database implementation, the repository will how the data repository that spring manages and service folder will hold the deligating business logic that spring also manages.
Step 4: Adding Spring and Redis properties to the project property file.
Next is to add all the properties we will be using. You can visit https://docs.spring.io/spring-boot/docs/current/reference/html/appendix-application-properties.html to understand most of the properties used.
I have changed theapplication.properties under the resource folder to application.yaml.
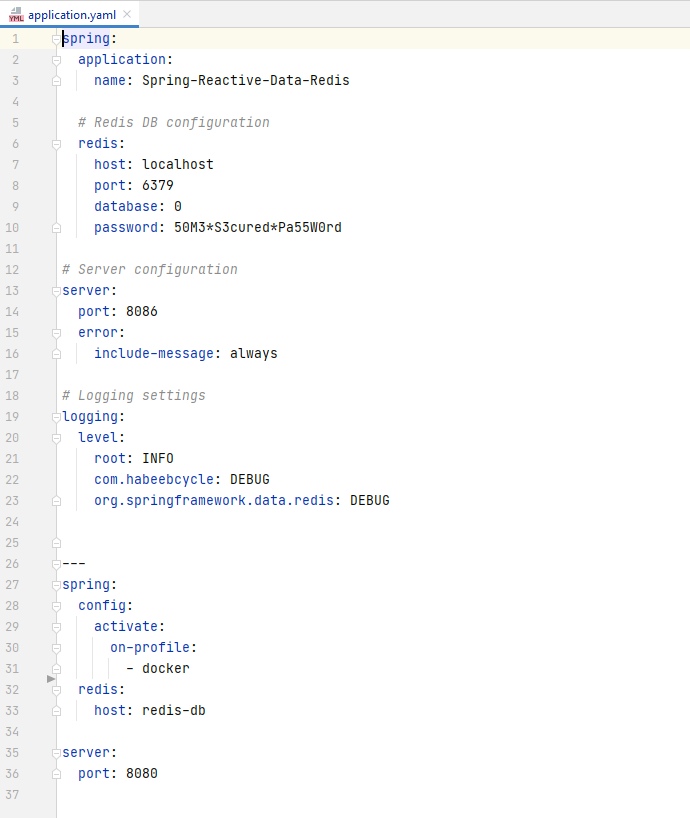
The file above has two documents embedded in one file. The first document is the default profile application properties while the other is the specific properties to the docker container. Line 1– 4: Specify the application name. Name it what you like. Line 6–10 defines Redis properties. If you didn’t set up your Redis cluster to use a password, you can either remove the password line 10 completely or enter an empty value at line 10 for the password. It is very important to use environment config for any of your secrets or passwords. For the purpose of this demo, I’m using a texted password that says ‘someSecuredPassword’. Later in the project, I will add the password to the Redis cluster. Line 13–16 indicates I will be using port 8086 (If you leave this, spring boot always run by default on port 8080. During this demo, my port 8080 is being used by another application on my computer. It will run on port 8080 on the Docker container) and to always include error message on the terminal. Line 19–23 shows what logging I need on my terminal.
Line 26 shows the beginning of the second document (docker profile). It will inherit all the default profile properties and use its own specific properties. For instance, the name of my Redis host in a container is redis-db and to use port 8080 in a docker profile and environment.
Step 5: Creating an entity class
Next is to create the entity object under the model package. The snippet below shows the User entity class which will be used to map the repository to the database. (User.java)
The above file is the User entity object, I don’t like using project Lombok in a demo application in order to show every part of the code, but you can use Lombok to clean up your project because it will automatically provide the constructors, getters and setters with just simple annotations.
Field id is used as a primary key which is not null and unique in the database. Note, we will be generating the value manually using UUID because Reactive Repositories are not supported by Redis and spring doesn’t provide any persistence API (JPA)for Reactive Redis.
Field version is used to implement optimistic locking on a data i.e. verifying that updates of an entity in the database do not overwrite a concurrent update. If the value of this field stored in the database is higher than the value of the version field in an update request, it indicates that the update is performed on stale data — the information to be updated has been updated by someone else since it was read from the database. Attempts to perform updates based on stale data will be prevented. When using JPA or data-mongodb, Spring automatically manages this process, but since Spring doesn’t provide repository data for Redis, we will implement this in our persistence operation. In the section on writing persistence tests, we will see tests that verify the optimistic locking mechanism to prevent updates to be performed on stale data.
Both the username and email fields will be made a unique field i.e. they will only store unique values. The field name is used to store the user’s name. The class represents a User object with a name and a unique username and email. It implements Serializable class so that it will be easily serialized and deserialized to object.
Step 6: Configuring Reactive Redis with Lettuce Connection Factory and Serialization.
Next is to create a configuration file inside the config folder. It will be annotated by @Configuration in order to make Spring Boot load it into context during booting. The snippet below shows the Redis configuration using the Lettuce Connection Factory in order to load some properties like password, host, username etc. (RedisConfiguration.java)
In the configuration above, some properties for the Redis is loaded via field injection with @Value annotation provided in the spring factory annotation package (Read more about the annotation here: https://medium.com/@habeebcycle/spring-value-annotation-tricks-be3f12f3e804).
Then two Beans were defined, the second one will use the first one as the connection factory to get into the Redis cluster. Since the reactive repositories are not supported by Redis, we will use the ReactiveRedisOperation to access Redis reactively. We would love to use a password on our Redis cluster, so we need a connection factory. We are using a Lettuce instead of Jedis because Lettuce offers a reactive way of connecting to Redis cluster. Lettuce returns RedisStandaloneConfiguration which had set all the Redis properties.
We also need to serialize whatever we are putting or getting back from Redis. Here we are using RedisSerializationContext with the key and hashKey are to be serialized by StringRedisSerializer while the value by our serialized User class and the hashValue by GenericJackson2JsonRedisSerializer.
Once the connection factory and serialization context are ready, we will use the ReactiveRedisTemplate that accepts both the connection factory and the serialization context to return the template as ReactiveRedisOperations which we are going to use later to access the data reactively in our repository.
Step 7: Implementing ReactiveCrudRepository interface and integrating it with Reactive Data Redis
Next is to create the user repository that will extend the interface ReactiveCrudRepository. Spring as provide all methods required of a repository in ReactiveCrudRepository interface, we will add our own custom methods as shown below (Available in the repository package as UserRepository.java)
As a Reactive Repositories are not supported by Redis, we will implement all the methods in our UserRepository and ReactiveCrudRepositoryinterfaces by using the ReactiveRedisOperations Bean created earlier.
The implementation class is in the persistence package and follows as shown in the snippet below
Some methods were fully implemented, and others can be fully implemented according to your business logic.
Line 20 defined the KEY (= "USERS")that will serve as the key of the user entity in the Redis database (like a table name in a relational database). Line 22–29 inject the ReactiveRedisOperations(ReactiveRedisTemplate) Bean and creates the object of aReactiveHashOperationsby calling opsForHashmethod of ReactiveRedisOperations(this.hashOperations = redisOperations.opsForHash();) the hashOperations will be used to perform all the required operations on Redis.
Line 31–34 overrides and implements the findByIdmethod of ReactiveCrudRepositoryand it returns the method get of ReactiveHashOperationsthat accepts the KEYand Idof the entity to search in the hash operations hashOperations.get(KEY, id); and returns a User Publisher.
Line 36–39 overrides and implements the findAllmethod of ReactiveCrudRepositoryand it returns the method values of ReactiveHashOperations which returns a Flux of all the user entity that corresponds to the KEY in the hash operations hashOperations.values(KEY); and returns a User Publisher.
Line 41–83 overrides and implements the save method of the ReactiveCrudRepository and it is implemented to save or update a user entity. It checks for uniqueness and non-emptiness of both the email and the username. If any of it is empty or not unique it throws an Exception. This demo is not a production-ready code because all the exceptions should be implemented for different scenarios. Try to create global exception handler and define all different error instances like BadRequest, NotFound, UnprocessEntity etc. exceptions It verifies that updates of an entity in the database do not overwrite a concurrent update. If the value of the version stored in the database is higher than the value of the version field in an update request, it indicates that the update is performed on stale data — the information to be updated has been updated by someone else since it was read from the database. Attempts to perform updates based on stale data will be prevented.
Line 186–197 actually is doing the job of saving and updating the user entity. It accepts the user entity to be saved or updated and a logical Publisher to check the uniqueness of both the username and the email. If the publisher is true, the method returns DuplicateKeyException, and if it is false, the method uses the put method of the hashoperations to insert or replace the user entity. This returns a true or a false publisher and is mapped to return the saved or updated user entity.
Line 85–90 and Line 92–97 override and implement findByUsername and findByEmail methods defined in the UserRepository interface. They used the values method of the hashOperations which returns a Flux of all the users with the KEY key. They apply the filter operation on the resulting Flux which returns any matching user or empty publisher.
Line 99–102 override and implements existsById method of the ReactiveCrudRepository interface. It uses the hasKey method of hashOperations passing the argument to be checked and returns a boolean publisher of true if the key exists or false if not.
Line 104–108 and line 110–114 override and implement existsByUsername and existsByEmail methods defined in the UserRepository interface. The check if there is an element in what findByUsername and findByEmail methods return. They use the hasElement method of a Publisher which returns a boolean publisher of true if they have an element or false if not.
Line 116–119 overrides and implements the count method of ReactiveCrudRepository interface. It counts all the entries in the hashOperations related to the KEY passed. It gets all the User publisher values of the passed key, applies the count method and returns a Long publisher.
Line 121–124 overrides and implements the deleteAll method of the ReactiveCrudRepository interface. It deletes all the entities of the KEY passed to the method from the database by using the delete method of the hashOperations. It deletes all the entries that are related to the KEY, returns a boolean publisher.
Line 126–129 and 131–134 override and implement the delete and deleteById methods of ReactiveCrudRepository interface. They remove an entry of a KEY and id passed as a parameter by using the remove method of the hashOperations. They remove an entry of the id and return a publisher.
Other methods to be overridden by our class were implemented as shown but return a null value. They can be implemented to suit our business logic or requirements. We have to implement them so as to satisfy the contract binding an interface and the implementing class (A class that implements an interface is required to define all the abstract methods in the interface unless it is an abstract class).
Step 8: Designing deligating service and controller layers
Both the Controller and Service layers are based on the implemented solution. UserController.java and UserService.java are the normal Spring RestController and Service respectively. Both classes are available in the controller and service package respectively.
In the controller, we created 6 different endpoints with a request mapping of /user. I am not going to explain the process in details because it is part of simple CRUD operations in Spring Boot. Each of the controller methods in turns called their corresponding service method whose in turns called the repository method. For instance, when the POST request is made to /user endpoint, line 29–32 takes up the request because it maps the endpoint and binds the request payload to the User object. It sends the user object to the Service layer by calling its saveUser method. This service method in turns makes a call to the repository save method implemented in Step 9.
Step 9: Writing the persistence tests to test the implemented UserRepository
Next is to test the implemented class UserRepository. The test class is shown below
On line 16, we are using the SpringBootTest and asking it to disable Redis password as follows properties = {"spring.redis.password="} by this, we can focus on testing the implementation rather than security.
Line 19 creates a RedisServer and pass the port 6379. We will start the server before the test and shut down the server after all the tests have been run.
Line 22 injects the UserRepository instance. We have asked Spring to manage it by making it a Spring Repository in the UserRepositoryImpl.java. We can now access all the method to run all the tests.
Line 37–55 declares the initialization to be performed before each test. It empties the database, creates a User and tests if it is successful and stores the saved user into the savedUser variable of line 25. The reactor StepVerifier is used to verify those assertions.
Line 57–88 performs several tests on create functionality. It verifies that a new User entity can be saved and fails if the username or the email is not unique i.e. they have already been used. It also verifies that an exception should occur if either or both the username and email is empty.
Line 91–114 performs several tests on the update functionality. It updates an entity and verifies that it is an update and not to create a new entity. Remember that the save method was used for both create and update. At the end of the test, it verifies that we still have only one entity in the database.
Line 117–133 performs the delete tests. It deletes an entity and verifies that it is no longer available in the database.
Line 136–151 performs a test on getting a User entity by either email or username.
Line 154–193 tests for duplicate errors. It verifies that the save or update operation should fail if the username or the email is not unique. Attempt to save or update an entity that has no unique username or email show throw a DuplicateKeyException error.
Line 196–234 performs the OptimisticLock on an entity. It verifies that only one instance of the same user entity can update the entity. It verifies that updates of an entity in the database do not overwrite a concurrent update. If the value of the version stored in the database is higher than the value of the version field in an update request, it indicates that the update is performed on stale data — the information to be updated has been updated by someone else since it was read from the database. Attempt to perform updates based on stale data should throw aOptimisticLockingFailureException.
Line 237–248 assertEqualUser is a utility method used to compare an entity in the tests since I didn’t override the equals method in the User class. It compares and assert different field in the User object and returns true if all the components are equal and false in case any of the components are not equal.
10. Conclusion
The main purpose of this writeup is to show how to use the Redis database reactively with Spring webflux. I have implemented all the ReativeCrudRepository methods provided by Spring webflux and perform unit testing on each method. The class below shows the test class that is used to perform web API testing on the Controller endpoints.
Like I said earlier, all the code here should be fine tune to fit into a production code as I have removed all the Exception handlers and other production-ready checks.
This is how I have implemented and used a Redis database reactively in one of my microservice projects. There are several ways to do the same thing. I am still learning in the field of Software and Data Engineering. Please do comment if there are any corrections, suggestions, additions.
The full code is on the GitHub repo at https://github.com/HabeebCycle/spring-reactive-redis-api
Clone it, run it and improve it.
Thank you for reading.
